
Skala zur Erfassung der Studieneinstiegsselbstwirksamkeit (SESW-Skala)
- Measurement Instrument
- Documentation
- Cite
- Terms of use
- CC-BY-NC-SA-4.0
- For use for other purposes contact the authors
Instruktion
Die Instruktion zur SESW-Skala lautet: Im Folgenden geht es um Ihren Studieneinstieg. Bitte geben Sie an, inwieweit Sie sich zutrauen, ...
Items
Items der Studieneinstiegsselbstwirksamkeits-Skala (SESW-Skala)
|
Nr. |
Item |
Polung |
Subskala |
|
1 |
...Ihren Stundenplan für die kommenden Semester selbstständig zusammenzustellen. |
+ |
FuS |
|
2 |
...die zur Verfügung stehende Zeit zur Prüfungsvorbereitung sinnvoll zum Lernen zu nutzen. |
+ |
FuS |
|
3 |
...auch unter Zeitdruck gute Studienleistungen zu erbringen. |
+ |
FuS |
|
4 |
...Ihre Prüfungsvorbereitungen selbstverantwortlich zu organisieren. |
+ |
FuS |
|
5 |
...eventuell auftretende Wissenslücken zu erkennen. |
+ |
FuS |
|
6 |
...eventuell auftretende Wissenslücken zu schließen. |
+ |
FuS |
|
7 |
...Fristen einzuhalten (zum Beispiel zur Abgabe von Hausarbeiten oder zur Anmeldung zu Prüfungen). |
+ |
FuS |
|
8 |
...auch bei kleineren Rückschlägen im Studium nicht den Mut zu verlieren. |
+ |
MuK |
|
9 |
...Ihr Vorwissen aus der Schule im Studium zu nutzen. |
+ |
MuK |
|
10 |
...Aufgaben aus Ihrem Studienfach durch logisches Denken zu lösen. |
+ |
MuK |
|
11 |
...die fachspezifischen Methoden in Ihrem Studienfach zu lernen. |
+ |
kH |
|
12 |
...komplexe fachliche Zusammenhänge zu verstehen. |
+ |
kH |
|
13 |
...große Mengen an Studieninhalten zu lernen. |
+ |
FuS |
Anmerkungen. FuS = Fristen und Strategien, MuK = Motivation und Kognition, kH = kognitive Herausforderungen.
Antwortvorgaben
Zur Beantwortung der Items steht eine fünfstufige Likertskala zur Verfügung: 1= gar nicht, 2 = eher nicht, 3 = teils teils, 4 = etwas, 5 = voll und ganz.
Auswertungshinweise
Alle Items der SESW-Skala sind positiv gepolt: Personen mit einer höheren Ausprägung des Konstrukts Studieneinstiegsselbstwirksamkeit sollten im Allgemeinen höhere Zustimmungswerte aufweisen. Eine Rekodierung der Items zu Auswertungszwecken ist dementsprechend nicht erforderlich. Zur Auswertung werden alle Items gleichermaßen berücksichtigt. Sie gehen folglich mit gleicher Gewichtung in die Bildung des Mittelwerts ein. Der Mittelwert liegt entsprechend dem Antwortformat im Bereich [1; 5] und stellt den Skalenwert da. Eine exemplarische Syntax zur Auswertung mit R und SPSS findet sich im Anhang.
Wurden einzelne Items nicht beantwortet, so wird empfohlen, für den jeweiligen Studien- oder Anwendungskontext und entsprechend den Eigenschaften des dann vorliegenden Datensatzes (z.B. Missing Completely at Random) individuell zu prüfen, ob Verfahren zur Imputation fehlender Werte sinnvoll eingesetzt werden können (Lüdtke et al. 2007; Rubin, 1976).
Die Auswertung der drei Subskalen (Fristen und Strategien; Motivation und Kognition; kognitive Herausforderungen) ist für den Anwendungskontext nicht relevant. Sie dient lediglich der differenzierten Betrachtung des Konstrukts zu Forschungszwecken. In Tabelle 1 ist für jedes Item angegeben, welcher Subskala es zugeordnet ist.
Anwendungsbereich
Die Skala wurde für die Befragung von Studieneinsteiger*innen entwickelt. Gemeint sind damit Studierende in grundständigen Studiengängen in ihrem ersten und zweiten Hochschulsemester. Die Skala eignet sich für den Einsatz in allen Fachbereichen und an Hochschulen jeglicher Art. Die Befragung kann dabei sowohl (hand-) schriftlich im Paper-Pencil-Modus als auch im Rahmen einer Online-Befragung durchgeführt werden.
Die Items wurden in den bisher durchgeführten Studien stets in der in Tabelle 1 aufgeführten Reihenfolge präsentiert. Ob eine randomisierte Präsentationsfolge der Items einen Effekt auf die Beantwortung dieser hat, wurde bislang noch nicht geprüft.
Die SESW-Skala dient der Erfassung der Selbstwirksamkeit im Studieneinstieg. Dabei differenziert sie insbesondere im Bereich niedriger Ausprägungen gut. Dementsprechend eignet sie sich besonders gut als Screening-Instrument zur Identifikation von Studieneinsteiger*innen, deren Studieneinstiegsselbstwirksamkeit vergleichsweise niedrig ist (siehe auch Kapitel 5 Gütekriterien). Die guten bis sehr guten Reliabilitätskennwerte (siehe auch Kapitel 5 Gütekriterien) rechtfertigen es, die SESW-Skala nicht nur als Instrument zur Diagnostik auf Gruppenebene, sondern auch für Individualdiagnostik einzusetzen. Die mittlere Bearbeitungszeit liegt bei etwa drei bis fünf Minuten. Dies ist eine erfahrungsbezogene Schätzung in Bezug auf die Paper-Pencil-Administration und inkludiert einleitende Worte der Administration. In Bezug auf die Online-Nutzung kann von 1,5 bis 3 Minuten ausgegangen werden. Diese Angaben beziehen sich auf N = 592 Personen am zweiten Messzeitpunkt der drei Längsschnittstudien (siehe Stichproben).
Studienabbruch ist ein weitverbreitetes Phänomen: Fast jeder dritte Studierende in den OECD-Ländern bricht sein Studium ab (OECD, 2016, 2017, 2018). In Deutschland im Speziellen liegt die mittlere Abbruchquote genau in diesem Bereich: In den grundständigen Studiengängen brechen ca. 28 % der Studierenden ihr Studium ab, die meisten von ihnen im Studieneinstieg (Semester 1 und 2, Heublein et al., 2017). Um beispielsweise von institutioneller Seite aus gezielt intervenieren zu können, ist eine zuverlässige Erfassung relevanter Prädiktoren notwendig. Zahlreiche empirische Befunde belegen, dass Selbstwirksamkeit einer der besten Prädiktoren für Studienabbruch und weitere Kriterien wie Studienzufriedenheit ist (Richardson et al., 2012; Robbins et al., 2004; Schneider & Preckel, 2017).
Das Konzept der Selbstwirksamkeit wurde ursprünglich von Bandura (1977) eingeführt. Wichtig ist die Unterscheidung zwischen allgemeiner und kontextspezifischer Selbstwirksamkeit. Mit allgemeiner Selbstwirksamkeit ist die grundlegende Überzeugung, Herausforderungen erfolgreich bewältigen zu können, gemeint. Spezifische Selbstwirksamkeit hingegen meint die Überzeugung, in einem bestimmten Kontext oder beim Ausführen spezifischer Handlungen erfolgreich sein zu können.
Das Konzept der Selbstwirksamkeit ist gemäß Bandura (1977) ein dynamisches Konzept. Das bedeutet, im Gegensatz zu Persönlichkeitseigenschaften im engeren Sinne, beispielsweise den Big 5 nach Costa und McCrae (1992), die als zeitlich relativ stabil angesehen werden (Trait), unterliegen Selbstwirksamkeitseinschätzungen ständigem Wandel.
Ein wichtiger Aspekt bei der Erfassung von Selbstwirksamkeit ist, dass kontextspezifische Maße bessere für kontextspezifische Vorhersagen (z.B. von Abbruch(-intentionen) und Zufriedenheit im Studieneinstieg) geeignet sind als generelle Maße (Betz & Hackett, 2006). Dies entspricht dem Symmetrie-Prinzip nach Brunswik (1955).
Zwar gibt es Skalen zur Erfassung der sogenannten „akademischen Selbstwirksamkeit" (zum Beispiel von Chemers et al., 2001), allerdings liegt bis heute keine spezifische Skala zur Erfassung der Selbstwirksamkeit im Studieneinstieg vor, die fachübergreifend anwendbar und auf die Population der Studienanfänger*innen in Deutschland zugeschnitten ist. So sind die meisten publizierten Skalen zur Erfassung von Selbstwirksamkeit im Studium (nicht im Studieneinstieg) für andere Bildungskontexte (andere Länder und Bildungssysteme) konzipiert und liegen oftmals auf Englisch vor.
Aus psychodiagnostischer Sicht kann in diesem Fall keineswegs per se davon ausgegangen werden, dass diese Skalen ebenso für die Verwendung im deutschen Hochschulkontext geeignet sind. Darüber hinaus ist in der Regel durch eine einfache Übersetzung einer englischsprachigen Skala ins Deutsche nicht gesichert, dass das deutschsprachige Instrument dann äquivalent zum englischsprachigen ist (International Test Commission, 2016). Beispielsweise muss die kulturelle Äquivalenz erst untersucht werden und kann nicht per se als gegeben angesehen werden (Rammstedt et al., 2011). Eine Ausnahme bildet die Skala von Peiffer et al. (2018), welche auf Deutsch vorliegt.
Sie bezieht sich allerdings explizit auf Psychologiestudierende (es werden konkrete Fächer innerhalb der Psychologie thematisiert) und ist wiederum nicht auf die Studieneingangsphase zugeschnitten, weshalb auch diese Skala für die fächerübergreifenden Erhebungen im Studieneinstieg als nicht geeignet erscheint. Diese „Lücke" soll die hier dargestellte Skala zur Erfassung der Studieneinstiegsselbstwirksamkeit füllen, die auf den Hochschulkontext in Deutschland zugeschnitten ist.Die Skalenentwicklung folgte dabei der vielfach zu findenden Empfehlung, Selbstwirksamkeit kontextspezifisch zu messen (Bandura, 1977; Betz & Hackett, 2006). Das bedeutet, dass zunächst die typischen Herausforderungen im Studieneinstieg identifizieren werden mussten, um die Skala so zu gestalten, dass sie das Maß an Zutrauen in die eigene Bewältigungskompetenz hinsichtlich eben dieser Herausforderungen erfasst. Als Kurzform des Skalennamens Skala zur Erfassung der Studieneinstiegsselbstwirksamkeit wird im Folgenden den Begriff SESW-Skala verwendet.
Itemkonstruktion und Itemselektion
Die Skalenentwicklung erfolgte in einem zweistufigen Vorgehen, wie es auch in gängigen Testkonstruktionslehrbüchern empfohlen wird (z.B. Eid & Schmidt, 2014). Im ersten Schritt wurden Items entwickelt, die die identifizierten Herausforderungen im Studieneinstieg abbilden. Im zweiten Schritt wurde diese erste Version der Skala einem quantitativen und einem qualitativen Vortest unterzogen. Ziel der quantitativen Vortests war es, die psychometrische Qualität der Skala zu untersuchen. Der qualitative Vortest sollte darüber hinaus Informationen liefern, inwiefern alle wichtigen Herausforderungen im Studieneinstieg von der Skala abgedeckt werden und ob die Befragten die Items so verstehen, wie sie gemeint sind. Die gewonnenen Informationen wurden anschließend zur Revision der ersten Version der Skala verwendet.
Schritt 1: Akademische Herausforderungen im Studieneinstieg
Da die Zielgruppe die Population der Studienanfänger*innen in Deutschland ist, lag es nahe, explizit die Herausforderungen für Studienanfänger*innen im deutschen Hochschulkontext als Ausgangsbasis für die Itemgenerierung zu verstehen. Um ein möglichst umfassendes Bild der akademischen Herausforderungen, denen die Studienanfänger*innen gegenüberstehen, zu erhalten, wurden drei Quellen herangezogen. Das waren zunächst (i) die Studierendenbefragung an der Justus-Liebig-Universität Gießen im Jahr 2016 (Ehrlich, 2016) und (ii) der zwölfte Studierendensurvey des BMBF (Ramm et al., 2014). Beide Studierendenbefragungen zeichnen sich dadurch aus, dass sie einen großen Stichprobenumfang aufweisen (N = 5263 Studierende und N = 647 Studienanfänger*innen) und dass über alle Fächergruppen hinweg befragt wurde. Zusätzlich wurde (iii) noch die Sicht der Lehrenden berücksichtigt, in dem fachübergreifenden Erkenntnisse aus der CHE-Professorenbefragung (Horstmann & Hachmeister, 2016) ebenfalls einbezogen wurden.
In der Studierendenbefragung an der Justus-Liebig-Universität Gießen (Ehrlich, 2016) wurden Studierenden aller Semester (neben anderen Themenbereichen) eine Liste von Kompetenzen (beispielsweise „Fähigkeit, wissenschaftliche Methoden anwenden zu können") vorgelegt und sie sollten sich selbst hinsichtlich dieser Kompetenzen einschätzen. Zudem wurde auch nach einer Selbsteinschätzung des Studienerfolgs gefragt („Ich bin mir sicher, dass ich das Studium erfolgreich bewältigen werde.").Diejenigen Kompetenzen, welche fächerübergreifend einen signifikanten Zusammenhang mit diesem
Erfolgskriterium aufwiesen, wurden als relevant für die hier beschriebene Skalenentwicklung betrachtet. Dabei können die Kompetenzen oder Fähigkeiten, die mit Studienerfolg assoziiert sind, durch einfache Umformulierung so ausgedrückt werden, dass sie eine Herausforderung beschreiben. So wird aus der oben exemplarisch genannten Kompetenz die „Herausforderung, wissenschaftliche Methoden anwenden zu können".
Die so gesammelten Herausforderungen wiesen zwar einen signifikanten Zusammenhang mit dem selbstberichteten Studienerfolg auf, waren allerdings nicht spezifisch von Studienanfänger*innen berichtet worden. Daher wurde zusätzlich eine Befragung eben dieser speziellen Subgruppe herangezogen. Im zwölften Studierendensurvey (Ramm et al., 2014) wurden unter anderem eben auch Studienanfänger*innen gezielt zur Studieneingangsphase befragt. Bargel (2015) bereitete die Daten dieser Teilstichprobe auf. Er berichtet, dass die Teilstichprobe hinsichtlich diverser Merkmale (Verteilung auf Hochschulen versus Fachhochschulen, Alter, Verteilung auf die Geschlechter, Verteilung auf die Studienfächer) repräsentativ für die Population der Studienanfänger*innen in Deutschland sei. In dieser Befragung wurde die Zielgruppe nach Schwierigkeiten im Studieneinstieg befragt. Dies kann hier als Synonym für Herausforderungen verstanden werden. Die drei großen Bereiche, in denen Schwierigkeiten berichtet wurden, waren: Leistungsanforderungen, Prüfungsvorbereitungen und Studienplanung (S. IV und S. 26). Die von Bargel (2015) aufgelisteten erlebten Schwierigkeiten wurden ebenfalls als relevant für die Skalenentwicklung erachtet.
Als dritte Quelle bei der Sammlung der akademischen Herausforderungen im Studieneinstieg wurde die Sicht der Lehrenden einbezogen. Dazu wurde die im Rahmen der CHE-Professorenbefragung von Horstmann und Hachmeister (2016) gewonnenen Erkenntnisse verwendet. Sie gingen explizit der Frage nach „Welche Fähigkeiten und Voraussetzungen sollten Studierende je nach Studienfach mitbringen?". Zwischen 2013 und 2015 wurden insgesamt circa 9.500 Professor*innen aus 32 verschiedenen Fächern befragt. Horstmann und Hachmeister (2016) berichten neben fachspezifischen Anforderungsprofilen auch solche Anforderungen, die fachübergreifend häufig genannt wurden: Abstraktes/ logisches/ analytisches Denkvermögen, selbstständiges/ selbstorganisiertes und diszipliniertes Lernen und Arbeiten, Selbstmanagement/ Bereitschaft zum Selbststudium sowie Lernbereitschaft/ Einsatz und Leistungsbereitschaft (S.6). Dabei sind die genannten Anforderungen wieder direkt in Herausforderungen übersetzbar. Diese aus Sicht der Lehrenden fachübergreifend wichtigen Aspekte wurde ebenfalls als relevant für die Skalenentwicklung betrachtet.Somit lag schließlich aus diesen drei Quellen eine Liste an akademischen Herausforderungen vor.
Tabelle 2 zeigt die aus den drei aufgeführten Quellen extrahierten Herausforderungen. Daraus wurden zunächst insgesamt zehn Items entwickelt, welche zur Abfrage der Selbstwirksamkeit bei der Bewältigung dieser dienen sollen. Aus abstrakten Begriffen wie „Zeitplanung" wurden Items entwickelt, die konkrete Handlungen aufführen, beispielsweise „die zur Verfügung stehende Zeit zur Prüfungsvorbereitung sinnvoll zum Lernen zu nutzen".Die aufgelisteten Herausforderungen zeigen hohe Überlappungen mit den Ergebnissen der qualitativen Interview-Studie von Trautwein und Bosse (2017), die 25 Studierende (11 Studienanfänger*innen und 14 Fortgeschrittene) der Universität Hamburg zum Thema Herausforderungen im Studium befragten.
Den Empfehlungen von Urdan und Pajares (2006) folgend, wurde die SESW-Skala so konzipiert, dass die in
Tabelle 2 genannten akademischen Herausforderungen aufgelistet sind und für jede auf einer fünfstufigen Likertskala angegeben werden soll, inwiefern man sich zutraut, diese zu bewältigen (1 = gar nicht bis 5 = voll und ganz).
Tabelle 2
Sammlung der Herausforderungen im Studieneinstieg aus drei Quellen
|
Quelle |
Herausforderung |
|
Ehrlich (2016) |
Beherrschung eigenes Fach, Arbeiten unter Druck, effizient auf Ziel hinarbeiten, Organisationsfähigkeit, analytische Fähigkeiten, Anwendung wissenschaftl. Methoden, eigene Wissenslücken zu erkennen und zu schließen |
|
Ramm et al. (2014) |
hohe Leistungsanforderungen, Prüfungsvorbereitungen (organisieren), Zeitplanung, aktive Teilnahme an Diskussionen, Kontakt zu Mitstudierenden finden |
|
Horstmann und Hachmeister (2016) |
logisches Denken, Selbstmanagement, Disziplin beim Studieren, Durchhaltevermögen zeigen, Leistungsmotivation aufbringen |
Ein Item (inklusive der vorgelagerten Instruktion) lautet dann beispielsweise: Im Folgenden geht es um Ihren Studieneinstieg. Bitte geben Sie an, inwieweit Sie sich zutrauen, Ihren Stundenplan für die kommenden Semester selbstständig zusammenzustellen.
Ein übergeordnetes Ziel bei der Skalenentwicklung war es, ein Screening-Instrument zu entwickeln. Das bedeutet, dass die Skala insbesondere im Bereich niedriger Selbstwirksamkeit gut differenzieren soll. Dies soll es ermöglichen, Studienanfänger*innen mit „auffällig" niedriger Selbstwirksamkeit zuverlässig zu identifizieren.
Schritt 2: Quantitativer und qualitativer Vortest
Insgesamt nahmen NVorstudie = 148 Studieneinsteiger*innen im Fach Psychologie am quantitativen Vortest teil. Davon gaben 18.2% an, männlich zu sein, 80.4% gaben an weiblich zu sein und 1.4% machten keine Angabe zu ihrem Geschlecht. Im Mittel waren sie M = 20.78 Jahre alt (SD = 2.92 Jahre). Neben der ersten Version der SESW-Skala (10 Items) bearbeiteten sie auch die Skala zur Erfassung der allgemeinen Selbstwirksamkeit (Schwarzer & Jerusalem, 1999). Dies sollte Daten zur (konvergenten) Konstruktvalidierung liefern. Tatsächlich zeigte sich eine erwartungsgemäß positive und hohe Korrelation zwischen den Skalen (r = .62, p = .001). Die Itemschwierigkeiten waren relativ hoch (p = .72 bis .79) und Itemtrennschärfen (rtt = .31 bis .49) lagen im erwartungsgemäßen Bereich für ein Screening-Instrument. Darüber hinaus wies die erste Version der SESW-Skala eine befriedigende interne Konsistenz auf: Cronbachs α = .72.
Während die Erkenntnisse aus dem quantitativen Vortest folglich recht vielversprechend waren, deckten die Erkenntnisse aus dem qualitativen Vortest noch Verbesserungsbedarf auf. Der qualitative Vortest umfasste fünf strukturierte Interviews mit Studierenden (80% weiblich). Hierbei kam die Technik des kognitiven Interviews (Leeuw et al., 2012) zum Einsatz; vornehmlich die think-aloud-Technik. Dabei wurden die Interviewpartner*innen zunächst gebeten, die Skala zu bearbeiten und dabei alle ihre Gedanken zu verbalisieren. Dies dient dazu festzustellen, ob beispielsweise einzelne Formulierungen missverständlich sind, beziehungsweise schwierig zu verstehen sind. Nach der Beantwortung aller Items wurde zudem explizit gefragt, ob irgendwelche Schwierigkeiten bei der Bearbeitung aufgefallen sind. Anschließend wurden die Interviewpartner*innen gefragt, ob aus ihrer persönlichen Erfahrung noch weitere typische Herausforderungen im Studieneinstieg auftreten, die in dieser ersten Version der Skala noch nicht enthalten waren. Wichtig war außerdem zu erfahren, wie die Formulierung „auch bei kleineren Rückschlägen im Studium nicht den Mut zu verlieren" wirkt. Die Formulierung sollte einerseits thematisieren, dass man im Studieneinstieg auch Misserfolge erleben kann, sollte aber andererseits nicht „verschreckend" wirken. Die Befragten äußerten, dass sie diese Formulierung als verständlich und unproblematisch ansehen würden.So gewonnene wertvolle Hinweise führten dazu, dass die Skala um weitere drei Items ergänzt wurde. Als zusätzliche akademische Herausforderungen kamen das Erlernen fachspezifischer wissenschaftlicher Methoden, das Verstehen komplexer Zusammenhänge und das Lernen großer Mengen an neuem Stoff dazu. Dies deckt sich mit den Befunden der drei zuvor genannten Quellen. Da sich diese zusätzlich von den Befragten genannten Aspekte in deren Augen noch nicht ausreichend differenziert in der Skala widerspiegelten, wurden diese drei Aspekte im Zuge der Revision in Form von zusätzlichen Items aufgenommen, wodurch sich das relative Gewicht der Items, die kognitive Leistungen thematisieren, erhöht hat.
Die revidierte Version der SESW-Skala
Nachdem die oben genannte Aspekte zur Revision der ersten Version der SESW-Skala geführt haben, liegt die aktuelle Version der SESW-Skala vor: Die Skala umfasst nunmehr 13 Items, die in Tabelle 1 dargestellt sind.
Stichproben
Im Folgenden werden erste empirische Befunde zur psychometrischen Qualität der SESW-Skala vorgestellt. Generell wurden in alle berichteten Analysen nur Daten von Personen einbezogen, die jeweils alle 13 Items der SESW-Skala bearbeitet hatten. Dieses strikte Ausschlusskriterium wurde angelegt, da es für eine Item- und Skalenanalyse dieses neuen Messinstruments ungünstig erschien, die Antworten auf die Items zu imputieren. Somit ergaben sich leicht reduzierte Stichprobenumfänge, was an der jeweiligen Stelle kenntlich gemacht wird. Die besagten drei Stichproben, die herangezogen wurden, sind folgendermaßen zu charakterisieren.
1. Vergleichsstichprobe
Die Stichprobe zur Erstellung von Vergleichsdaten umfasst n1 = 1842 Studienanfänger*innen der Justus-Liebig-Universität Gießen, die an der online durchgeführten Studieneingangsbefragung im Jahr 2018 ohne Vergütung teilnahmen. Im Mittel waren sie M = 20.8 Jahre (SD = 3.4 Jahre) alt. 29.0% gaben an, männlich zu sein, 64.0% weiblich, und weniger als 1.0% ordneten sich der Geschlechtskategorie „inter" zu, die restlichen Teilnehmer machten keine Angaben zu ihrem Geschlecht. Verglichen mit den Daten der Zielpopulation (Statistisches Bundesamt, 2018) sind die weiblichen Studierenden in dieser Stichprobe somit überrepräsentiert.
Der Übersichtlichkeit wegen waren in der Studieneingangsbefragung die Studienfächer in Fachcluster aufgeteilt. In dieser Vergleichsstichprobe fielen auf die verschiedenen Fachcluster folgende Stichprobenanteile ab: 19.8% Geisteswissenschaften, 28.4% Naturwissenschaften, 11.8% Medizin, 24.2% Lehramststudiengänge, 9.5% Recht und Wirtschaft und 5% Psychologie. Somit liegt mit dieser Vergleichsstichprobe zwar keine gänzlich für die Population der Studienanfänger*innen in Deutschland (vgl. Statistisches Bundesamt, 2018) repräsentative Stichprobe vor, jedoch kann davon ausgegangen werden, dass aufgrund der großen Fächerheterogenität nicht mit bedeutsamen Verzerrungen aufgrund einer starken Überrepräsentierung einzelner Fächer bzw. Fachkulturen zu rechnen ist.
Aus diesem Datensatz mussten 276 Fälle (13.03%) wegen einzelner nicht beantworteter SESW-Items für die Analysen ausgeschlossen werden, woraufhin der oben genannte Umfang der Vergleichsstichprobe von n1 = 1842 Personen resultierte. In Anbetracht des Erhebungskontextes (freiwillige Teilnahme, keine Vergütung) und der Tatsache, dass die SESW-Skala weit hinten in der Umfrage angeordnet war, ist dieser Anteil als akzeptabel einzustufen.
2. Längsschnittliche Validierungsstichprobe
Diese Stichprobe besteht insgesamt aus n2Start = 1086 Studienanfänger*innen verschiedener Universitäten in Deutschland. Es handelt sich um den aggregierten Datensatz aus drei Längsschnittstudien (Studienanfänger der Wintersemester 16/17, 17/18 und 18/19). Wie im Abschnitt Messinvarianz im Detail dargelegt, erwies sich die SESW-Skala als messinvariant über diese drei Jahrgänge, was die Aggregation der Daten legitimiert. In allen drei Studien wurden die Daten im Rahmen eines Online-Fragebogens erhoben. Die Studienteilnehmer*innen konnten auf Wunsch an einer Verlosung von Einkaufsgutscheinen (Wert: 25 €) teilnehmen. Im ersten Jahrgang wurde zusätzlich ein Tablet verlost.
In dieser Gesamtstichprobe gaben 19.4% männlich zu sein, 78.3% gaben an, weiblich zu sein, die restlichen Teilnehmer machten keine Angabe zu ihrem Geschlecht. Das Alter lag im Mittel bei M = 20.79 Jahren (SD = 4.01 Jahre). Wie in Longitudinalstudien nicht unüblich (Gold & Souvignier, 2005), ist auch in diesen Studien über die Verlaufsdauer von jeweils neun Monaten (Studieneinstieg: Semester 1 und 2) eine Panelmortalität von ca. 50% zu verzeichnen. Für die Analyse der prognostischen Validität der Skala (Vorhersage von Abbruchintention und Studienzufriedenheit zum Ende der Studieneingangsphase) konnten somit nur diejenigen herangezogen werden, die auch beim jeweils dritten Messzeitpunkt noch teilnahmen. Daraus resultiert nach der Bereinigung der Datensätze ein reduzierter Stichprobenumfang für diese longitudinalen Analysen von n2final = 424 (17.7% männlich, 80.4% weiblich, M = 20.85 Jahre, SD = 3.84 Jahre).
Hinsichtlich der Verteilung auf die Studienfächer ist diese Stichprobe sehr heterogen, aber ebenfalls nicht gänzlich repräsentativ für die Population der Studienanfänger*innen in Deutschland (Statistisches Bundesamt, 2018): 21.3% Naturwissenschaften, 24.8% Medizin oder Psychologie, 13.7% Sprachen/ Literatur/ Kultur, 22.2% Erziehungswissenschaften, 18.0% Wirtschaft, Recht oder sonstige Fächer.
Für die spätere Interpretation der Ergebnisse ist Folgendes zu berücksichtigen: Diejenigen, die bis inklusive des letzten Messzeitpunktes an den Studien teilnahmen, sprich deren Daten in die Analysen der prädiktiven Validität einbezogen werden konnten, unterschieden sich in ihrer berichteten Studieneinstiegsselbstwirksamkeit (resp. SESW-Skalenwert) signifikant von denen, die während der neunmonatigen Studienlaufzeit die Teilnahme abbrachen. Diejenigen, die nicht an der kompletten Studie teilnahmen berichteten im Mittel eine niedrigere SESW: t (1078) = -2.098, p = .036.
Aus diesem Datensatz mussten keine Fälle wegen nicht beantworteter SESW-Items für die Analysen ausgeschlossen werden. Dies mag daher rühren, dass die Datenerhebung online durchgeführt wurde und ein Hinweis angezeigt wurde, falls jemand (aus Versehen) ein Item nicht beantwortet hatte. Die Person wurde dann darauf hingewiesen, dass es wünschenswert ist, dass alle Items beantwortet werden (technisch „erzwungen“ wurde die Antwort jedoch nicht).
3. Querschnittliche Validierungsstichprobe
An dieser Validierungsstudie nahmen insgesamt n3 = 148 Personen teil. 28 davon (23%) mussten für die Analysen ausgeschlossen werden, weil sie nicht alle 13 SESW-Items beantwortet hatten. Die verbleibende Stichprobe umfasst n3final = 120 Studienanfänger*innen der Fächer Chemie/ Lebensmittelchemie (72.5%) und Psychologie. 40.8% gaben an, weiblich zu sein, 41.7% männlich und 17.5% machten keine Angabe hinsichtlich ihres Geschlechts. Aus Gründen des Datenschutzes wurde das Alter in Kategorien abgefragt: weniger als 2% waren jünger als 18 Jahre, 51.7% waren zwischen 18 und 19 Jahre alt, 17.5% zwischen 20 und 21 Jahre alt, 6.7% waren zwischen 22 und 23 Jahre alt, 2.5% zwischen 24 und 25 Jahre alt und 5% waren älter als 25 Jahre. Die restlichen 15% der Teilnehmer machten keine Angaben zu ihrem Alter.
Itemanalysen
Präanalysen
Die im Folgenden berichteten Analysen wurden unter Verwendung der Software R (R Core Team, 2018) und IBM SPSS Statistics (Version 21, IBM Corp, 2012) durchgeführt. Zunächst wurde die Verteilung des SESW-Skalenwerts in der Vergleichsstichprobe auf Normalität geprüft: M = 4.02 (SD = 0.55), die Schiefe beträgt Sch = -.50 (SE = 0.06) und die Kurtosis K = 0.52 (SE = 0.11). Sowohl der durchgeführte Kolmogorov-Smirnov-Test als auch der Shapiro-Wilk-Test wurden signifikant: D (1842) = .989, p < .01 and W (1842) = .979, p < .01. Das bedeutet, dass keine Normalverteilung vorliegt. Als Konsequenz mussten für die folgenden Analysen „sofern möglich" nichtparametrische Verfahren verwendet werden. Konkret bedeutet das in erster Linie, dass Spearman- statt Pearson-Korrelationen berichtet werden. Die Daten dieser Vergleichsstichprobe wurden für die Analysen sämtlicher im Folgenden berichten Itemstatistiken herangezogen. Zur Berechnung der Reliabilitäts- und Validitätskoeffizienten wurden sie teilweise ebenfalls verwendet, teilweise aber auch die Daten aus den beiden anderen aufgeführten Stichproben. Es wird für jede der berichteten Analysen jeweils angegeben, auf welcher Stichprobe sie basiert.
Faktorielle Validität
Weiterhin sollte die interne Struktur der SESW-Skala getestet werden. Folgende hierarchische Struktur wurde auf Basis der Iteminhalte postuliert: Auf der obersten Ebene findet sich ein Generalfaktor: Studieneinsteigsselbstwirksamkeit SESW. Auf der darunter liegenden Ebene gibt es drei Faktoren erster Ordnung: Fristen und Strategien (FuS), Motivation und Kognition (MuK) und kognitive Herausforderungen (kH). Hierbei laden unterschiedliche viele Items (manifeste Variablen) auf den drei Faktoren. Auf dem Faktor FuS laden acht Items (Item 01 bis Item 07 und Item 13), darunter Item 03 „die zur Verfügung stehende Zeit zur Prüfungsvorbereitung sinnvoll zum Lernen zu nutzen". Auf dem Faktor MuK laden drei Items (Item 08 bis Item 10), wie zum Beispiel Item 08 „auch bei kleineren Rückschlägen im Studium nicht den Mut zu verlieren". Auf dem dritten Faktor kH laden die restlichen zwei Items (Item 11 und 12), beispielsweise Item 12 „komplexe fachliche Zusammenhänge zu verstehen".
Empirisch getestet wurde dieses hierarchische Modell anhand der Vergleichsstichprobe von N = 1842 Studienanfänger*innen unter Verwendung des lavaan-Pakets in R (Rosseel, 2012). Abbildung 1 zeigt das Strukturgleichungsmodell, welches die hierarchische Struktur der SESW-Skala darstellt. Hierbei erwies sich das Modell als gut bis akzeptabel geeignet zur Beschreibung der Daten aus dieser Stichprobe (verwendeter Schätzer: Maximum Likelihood: SRMR = .041, CFI = .928, RMSEA = .075 [.070; .080]. Gemäß weithin verbreiteten Cut-off-Werten für diese Modellfitindizes (Hooper et al. 2008; Hu & Bentler, 1998) kann dies als Beleg für die postulierte hierarchische Struktur der Studieneinstiegsselbstwirksamkeit gelten.
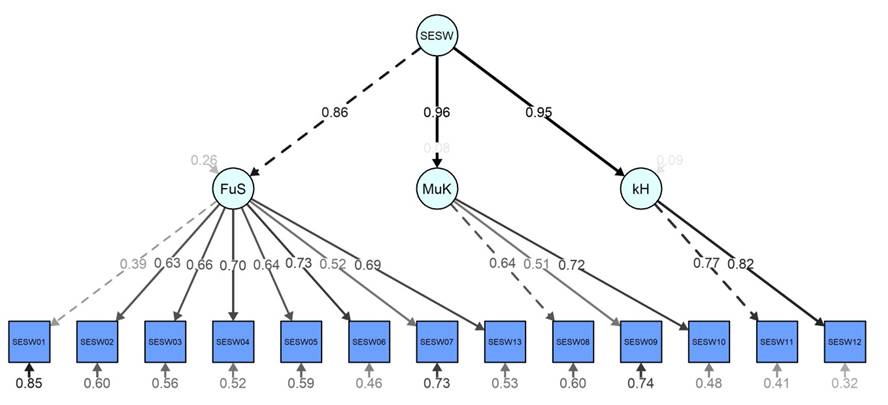
Abbildung 1. Hierarchisches Modell der SESW-Skala (standardisierte Koeffizienten) mit einem Generalfaktor (SESW) und drei Faktoren erster Ordnung: Fristen und Strategien (FuS), Motivation und Kognition (MuK) und kognitive Herausforderungen (kH), N = 1842.
Im Anwendungskontext ist die Verwendung des Generalfaktors (manifestiert im SESW-Skalenwert) sinnvoll. Für weitere faktoranalytische Untersuchungen der latenten Variable Studieneinstiegsselbstwirksamkeit sowie für die Einordnung des Konstrukts in ein nomologisches Netz inklusive der Abgrenzung gegenüber verwandten Konstrukte wie dem allgemeinen Selbstwert oder Ähnlichem sollten zwecks Gewinnung detaillierter Einblicke auch die Faktoren erster Ordnung berücksichtigt werden.
Itemkennwerte
Itemkennwerte nach KTT
In diesem Abschnitt werden die Itemstatistiken aus der Perspektive der klassischen Testtheorie (KTT) dargestellt. Es handelt sich hierbei um die Itemschwierigkeit und die Itemtrennschärfe. Tabelle 3 zeigt für jedes Item den Mittelwert, die Standardabweichung sowie die beiden genannten Itemkennwerte. Weiterhin ist angegeben, wie die interne Konsistenz (gemessen als Cronbachs α) ausfiele, würde das jeweilige Item weggelassen werden. Die Itemschwierigkeiten liegen etwas über dem im Allgemeinen empfohlenen Bereich um .50 (Schmidt-Atzert & Amelang, 2012). Bedenkt man allerdings, dass (i) die SESW-Skala kein Leistungstest, sondern im weitesten Sinne eher ein Persönlichkeitsfragebogen ist und (ii) dass die SESW-Skala als Screening-Instrument insbesondere im Bereich niedriger Ausprägung der Studieneinsteigsselbstwirksamkeit gut differenzieren können soll, können die beobachteten Itemschwierigkeiten als zufriedenstellend eingestuft werden (Moosbrugger & Kelava, 2012). Besser wäre es allerdings, wenn es zumindest auch ein Item in der Skala gäbe, welches eine geringere Popularität aufweist und somit auch im Bereich höherer Ausprägung besser differenzieren könnte.
Mittelwert, Standardabweichung sowie Schwierigkeit und Trennschärfe
|
Item |
Mittelwert |
Standardabweichung |
Schwierigkeit |
Trennschärfe |
|
SESW01 |
4.08 |
0.95 |
0.82 |
0.36 |
|
SESW02 |
3.97 |
0.82 |
0.79 |
0.56 |
|
SESW03 |
3.80 |
0.85 |
0.76 |
0.61 |
|
SESW04 |
4.10 |
0.82 |
0.82 |
0.63 |
|
SESW05 |
3.99 |
0.82 |
0.80 |
0.59 |
|
SESW06 |
3.98 |
0.79 |
0.80 |
0.67 |
|
SESW07 |
4.37 |
0.80 |
0.87 |
0.48 |
|
SESW08 |
3.89 |
0.94 |
0.78 |
0.57 |
|
SESW09 |
3.92 |
1.03 |
0.78 |
0.45 |
|
SESW10 |
4.11 |
0.79 |
0.82 |
0.60 |
|
SESW11 |
4.19 |
0.73 |
0.84 |
0.65 |
|
SESW12 |
4.03 |
0.78 |
0.81 |
0.68 |
|
SESW13 |
3.88 |
0.86 |
0.78 |
0.63 |
Anmerkungen. N = 1842.
Für alle Items außer Item 01 liegt die Trennschärfe im empfohlen Bereich [.40; .70] (Moosbrugger & Kelava, 2012). Fast alle Items weisen sogar eine Trennschärfe über .50 auf, was im Allgemeinen als gut eingestuft wird. Insgesamt zeigt sich zudem das, was auf Skaleneben bereits oben beschrieben ist: Die befragten Studienanfänger*innen tendierten zu relativ hohen Zustimmungsraten bei allen Items.
Itemkennwerte nach IRT
In Ergänzung zur Darstellung der Itemstatistiken aus der Perspektive der KTT, sollen an dieser Stelle nun die entsprechenden Itemkennwerte aus der Perspektive der Item Response Theory (IRT) dargelegt werden. Für deren Berechnung mit Hilfe des mirt-Pakets in R (Chalmers, 2012) wurde das Graded Response Model (GRM) nach Samejima (1969) zu Grunde gelegt, da dieses explizit für polytome Items mit geordneten Antwortkategorien postuliert wurde und bei der vorliegenden Anzahl an Items sowie den vorliegenden Stichprobenumfängen zuverlässig angewendet werden kann (Lubbe & Schuster, 2019). Hierbei wurde die Methode des EM-Algorithmus verwendet. Tabelle 4 zeigt die Itemdiskrimination αi sowie die vier Schwellenparameter ik (k=1 bis 4 bei fünf Antwortkategorien) für alle 13 Items.
Itemdiskrimination sowie Schwellenparameter (basierend auf dem GRM, Samejima, 1969)
|
Item |
αi |
βi1 |
βi2 |
βi3 |
βi4 |
|
SESW01 |
0.79 |
-5.52 |
-3.72 |
-1.60 |
0.64 |
|
SESW02 |
1.52 |
-4.29 |
-2.75 |
-0.88 |
0.89 |
|
SESW03 |
1.79 |
-3.58 |
-2.17 |
-0.51 |
1.12 |
|
SESW04 |
1.87 |
-4.48 |
-2.46 |
-0.97 |
0.51 |
|
SESW05 |
1.72 |
-4.18 |
-2.42 |
-0.90 |
0.80 |
|
SESW06 |
2.33 |
-3.58 |
-2.32 |
-0.77 |
0.76 |
|
SESW07 |
1.24 |
-5.25 |
-3.34 |
-1.79 |
-0.13 |
|
SESW08 |
1.56 |
-3.62 |
-2.08 |
-0.69 |
0.81 |
|
SESW09 |
1.15 |
-3.85 |
-2.27 |
-0.87 |
0.67 |
|
SESW10 |
1.8 |
-3.98 |
-2.59 |
-1.09 |
0.57 |
|
SESW11 |
2.31 |
-4.31 |
-2.74 |
-1.18 |
0.42 |
|
SESW12 |
2.57 |
-3.38 |
-2.26 |
-0.88 |
0.69 |
|
SESW13 |
2.05 |
-3.33 |
-2.01 |
-0.64 |
0.89 |
Anmerkungen. N = 1842. αi steht für die Itemdiskrimination von Item i, βik steht für den Punkt auf dem latenten Kontinuum, an dem für Item i der Cut-off-Wert zwischen Kategorie k und k+1 liegt.
Passend zu den Ergebnissen der Analysen nach KTT, kann auch aus Perspektive der IRT für alle Items außer Item 01 (α1 = .79) festgehalten werden, dass der Steigungsparameter im gewünschten Bereich von [0.80; 2.50] (Ayala, 2013) liegt. Wie erwartet erwies sich für alle Items die Annahme der geordneten Kategorie als haltbar, was daran ersichtlich wird, dass die i1 bis i4 für alle Items in aufsteigender Reihenfolge geordnet sind.
Abbildung 2 zeigt die sogenannten Item-Tracelines für die Items, deren Inspektion weitere Details offenlegt. Item-Tracelines sind eine Darstellung der Kategoriewahrscheinlichkeiten, also der Wahrscheinlichkeiten, mit der eine bestimmte Antwortkategorie beim Vorliegen einer bestimmten Ausprägung der latenten Variable, angekreuzt wird. Hier ist für jede der fünf Antwortkategorien die jeweilige Kurve in einer anderen Farbe abgetragen. Betrachtet man die Kurven für jedes einzelne Item, so wird deutlich, dass für alle Items wie gewünscht alle fünf Kurven eingipfelig sind. Zudem überragt bei allen Items (außer bei Item 01) jede Kurve am Punkt ihres Maximums auch alle vier anderen Kurven. Das bedeutet, dass bei Item 02 bis Item 13 jede Antwortkategorie bei einer bestimmten Ausprägung der Studieneinstiegsselbstwirksamkeit am wahrscheinlichsten gewählt wird. Bei Item 01 hingegen ist die Kurve für die höchste Antwortkategorie (gelb) stark verbreitert: Bereits bei einer mittleren Ausprägung der latenten Variable Studieneinstiegsselbstwirksamkeit ist es am wahrscheinlichsten, dass Personen die höchste Antwortkategorie wählen. Dies ist also ein weiterer Beleg dafür, dass Item 01 eine hohe Schwierigkeit und eine niedrige Trennschärfe aufweist bzw. die Antworten zu diesem Item einen starken Deckeneffekt aufweisen. Relativ gesehen erweist sich dieses Item somit als das mit der niedrigsten psychometrischen Qualität innerhalb der SESW-Skala.
Bei genauerer Inspektion von Tabelle 4 wird deutlich, dass sich der oben beschrieben Deckeneffekt auch darin zeigt, dass für alle Items die Kennwerte i1 bis i3 negativ sind. Das bedeutet, dass sogar Personen mit relativ niedrig ausgeprägter Studieneinstiegsselbstwirksamkeit nicht nur in die untersten Antwortkategorien ankreuzten, sondern häufig die ersten vier Antwortkategorien genutzt haben. Anders ausgedrückt: Auch Personen mit vergleichsweise niedriger Studieneinstiegsselbstwirksamkeit trauen sich oftmals zumindest „teils teils" (Wortlaut der mittleren Antwortkategorie) zu, die in der SESW-Skala aufgeführten Herausforderungen zu bewältigen.
Weiterhin zeigt die Testinformationskurve (Abbildung 3), dass die SESW-Skala bei niedrigen Ausprägungen der latenten Variable am besten differenziert, da hier die Maxima der Kurve liegen (links der Null auf der x-Achse).
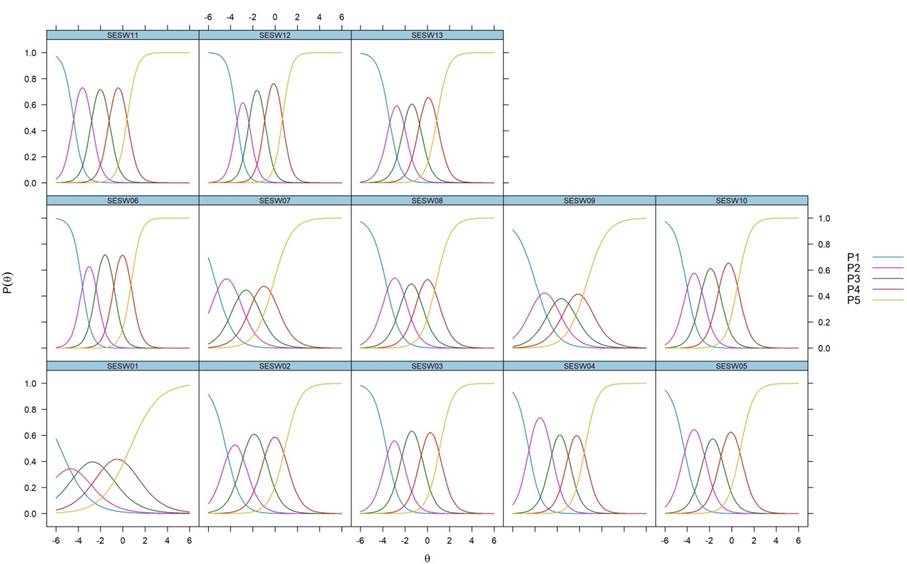
Abbildung 2. Item-Tracelines (basierend auf dem GRM nach Samejima, 1969).
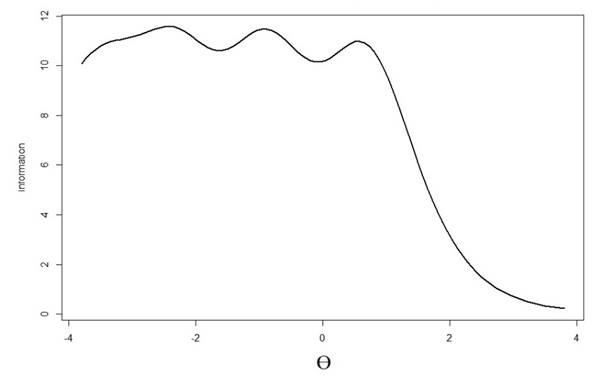
Abbildung 3. Testinformationskurve der SESW-Skala.
Betrachtet man die Iteminformationskurven (Abbildung 4), so erkennt man ganz ähnliche Kurvenverläufe auch separat für fast alle Items. Auffällig ist hierbei jedoch, dass insbesondere Item 01 diese Kurve sehr flach verläuft: Entsprechend der bereits berichteten geringen Trennschärfe von Item 01 ist auch der Informationsgehalt über die verschiedenen möglichen Ausprägungen der latenten Variable Studieneinstiegsselbstwirksamkeit hinweg (abgetragen auf der x-Achse in Abbildung 4) relativ gering.
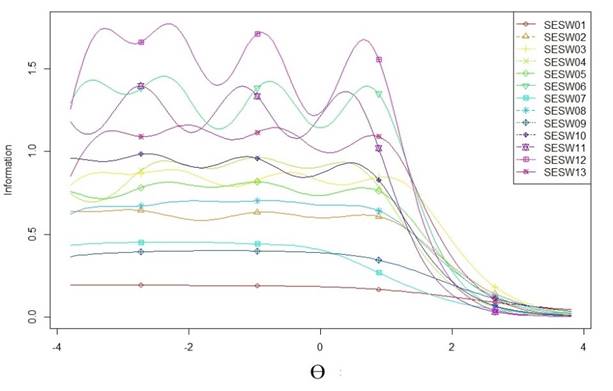
Abbildung 4. Iteminformationskurven für die 13 Items der SESW-Skala.
Objektivität
Um die Durchführungsobjektivität sicherzustellen, sollte die SESW-Skala sowohl bei Paper-Pencil-Befragungen als auch bei Online-Befragungen stets in der oben dargestellten Itemreihenfolge und mit dem vorgestellten fünfstufigen Antwortformat administriert werden. Zudem ist keine Zeitbegrenzung für die Bearbeitung vorgesehen.
Auswertungsobjektivität kann als gegeben angesehen werden, wenn den Antwortkategorien die numerischen Werte (1 bis 5) wie dargestellt zugeordnet werden und der Skalenwert als gleichgewichteter Mittelwert über alle dreizehn Items errechnet wird.
Die Interpretationsobjektivität schlussendlich kann beispielsweise dadurch gewährt werden, dass die unten dargestellten Vergleichswerte herangezogen werden.
Reliabilität
Vor der Untersuchung der Reliabilität der SESW-Skala im Sinne der internen Konsistenz wurden die Korrelationen nullter Ordnung zwischen den Items berechnet. Aufgrund der nichtparametrischen Verteilung der SESW-Skalenwerte wurden nichtparametrische Spearman-Korrelationen (rs) verwendet. Wie Tabelle 5 zeigt, weisen die Items untereinander mittlere bis enge Zusammenhänge auf.
Nichtparametrische Korrelationen (nach Spearman) der 13 Items der SESW-Skala
|
Item |
01 |
02 |
03 |
04 |
05 |
06 |
07 |
08 |
09 |
10 |
11 |
12 |
|
SESW01 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
SESW02 |
0.23 |
1 |
|
|
|
|
|
|
|
|
|
|
|
SESW03 |
0.23 |
0.48 |
1 |
|
|
|
|
|
|
|
|
|
|
SESW04 |
0.26 |
0.50 |
0.46 |
1 |
|
|
|
|
|
|
|
|
|
SESW05 |
0.28 |
0.36 |
0.36 |
0.45 |
1 |
|
|
|
|
|
|
|
|
SESW06 |
0.25 |
0.46 |
0.47 |
0.46 |
0.54 |
1 |
|
|
|
|
|
|
|
SESW07 |
0.24 |
0.37 |
0.28 |
0.47 |
0.31 |
0.35 |
1 |
|
|
|
|
|
|
SESW08 |
0.23 |
0.33 |
0.42 |
0.37 |
0.34 |
0.41 |
0.29 |
1 |
|
|
|
|
|
SESW09 |
0.13 |
0.30 |
0.30 |
0.30 |
0.36 |
0.36 |
0.23 |
0.36 |
1 |
|
|
|
|
SESW10 |
0.27 |
0.28 |
0.41 |
0.34 |
0.41 |
0.44 |
0.25 |
0.44 |
0.41 |
1 |
|
|
|
SESW11 |
0.24 |
0.34 |
0.37 |
0.39 |
0.42 |
0.48 |
0.33 |
0.41 |
0.37 |
0.53 |
1 |
|
|
SESW12 |
0.25 |
0.32 |
0.47 |
0.40 |
0.44 |
0.51 |
0.27 |
0.47 |
0.35 |
0.56 |
0.61 |
1 |
|
SESW13 |
0.23 |
0.46 |
0.47 |
0.46 |
0.36 |
0.47 |
0.35 |
0.41 |
0.31 |
0.39 |
0.48 |
0.56 |
Anmerkungen. Alle Korrelationen signifikant auf dem Niveau ** p <.01, N = 1842.
Interne Konsistenz
Vor diesem Hintergrund sind die Befunde zur internen Konsistenz, welche unter Verwendung des psych-Pakets in R (Revelle, 2018) berechnet wurden, wenig überraschend: Für die SESW-Skala ergab sich anhand der Daten der Vergleichsstichprobe: Cronbachs α = .88 (KI95% [.88; .89]). Das verwandte Maß McDonalds ω (Schätzer: minimum residual solution; OLS) fiel sogar noch etwas höher aus (ω total = .90), wobei dieser Schätzer analog zu Cronbachs α interpretiert werden kann. Dies ist als hohe interne Konsistenz zu beurteilen.
Test-Retest-Reliabilität
Als zusätzliches Maß für die Reliabilität der SESW-Skala wurde die Test-Retest-Reliabilität berechnet. Gemäß der Definition von (kontextspezifischer) Selbstwirksamkeit als dynamisches Konstrukt, welches der ständigen Veränderung durch neue Erfahrungen unterliegt, ist aus theoretischer Sicht ein Stabilitätskoeffizient mittlerer Höhe für die SESW-Skala zu erwarten. Genau das zeigte sich auch: Die Test-Retest-Reliabilität belief sich über die ersten vier Monate der Längsschnittstudien auf rt1t2 = .48 (n = 589, p < .01) und über die Gesamtlaufzeit der Längsschnittstudien (9 Monate) auf rt1t3 = .35 (p < .01, n = 485).
Diese Ergebnisse weisen auf eine sehr gute interne Konsistenz sowie eine erwartungsgemäß mittlere zeitliche Stabilität (siehe Kapitel 3 Theoretischer Hintergrund) im Sinne der Test-Retest-Reliabilität der SESW-Skala hin.
Validität
Konstruktvalidität
Wie bereits bei der Analyse der Reliabilität, wurden auch bei der Validitätsanalyse aufgrund der nichtparametrischen Verteilung der SESW-Skalenwerte stets nichtparametrische Spearman-Korrelationen (rs) berechnet. Anhand der oben beschriebenen kumulierten Stichprobe des jeweils ersten Messzeitpunktes in allen drei Jahrgängen konnte einen signifikanter, positiver Zusammenhang zwischen der SESW-Skala und der Skala zur Erfassung der allgemeinen Selbstwirksamkeit (Schwarzer & Jerusalem, 1999, 10 Items, Cronbachs α = .85) in Höhe von rs = .57, p < .001, N = 1079 (längsschnittliche Validierungsstudie mit fallweisem Ausschluss) beobachtet werden.
Weiterhin erwies sich erwartungsgemäß der Zusammenhang zwischen dem SESW-Skalenwert und dem Testwert in einem kognitiven Fähigkeitstest als nicht bedeutsam (rs = .15 p = .096). Zum Einsatz kam bei der oben beschriebenen dritten Stichprobe der Gießener kognitive Kompetenzentest (GkKT) mit 66 Items (Ulfert, Ott, Bothe & Kersting; Petri et al., 2019), der eine Reliabilität von Cronbachs α = .88 (N = 120, querschnittliche Validierungsstudie) aufwies.
Diese Prüfungen entsprechen der Strategie der konvergenten und diskriminanten Konstruktvalidierung.
Kriteriumsvalidität
Wie bereits oben dargelegt, kann davon ausgegangen werden, dass die Intention, das Studium abzubrechen, mit der Selbstwirksamkeit im Studieneinstieg assoziiert ist. Im Rahmen der beschriebenen drei Längsschnittstudien wurde am jeweils ersten Befragungszeitpunkt (neben diversen anderen Skalen) auch die SESW-Skala eingesetzt. Am dritten und letzten Befragungszeitpunkt wurden die Abbruchintentionen erhoben (siehe auch 4.1.1). Die Items dafür, welche an vorherige Studien angelehnt waren (Ehrlich, 2016; Respondek et al. 2017), lauteten: „Ich habe vor, das Studium zu einem erfolgreichen Abschluss zu bringen." und „Ich habe vor, das Studium abzubrechen.". Auf einer siebenstufigen Likertskala sollte die Zustimmung angegeben werden (stimme gar nicht zu = 1 bis stimme voll und ganz zu = 7). Die Antworten auf das erste Item wurden invertiert und die Items dann durch Aufsummieren der beiden Antwortscores zu einem Skalenwert zusammengefasst. Hierbei gingen etwas weniger Datensätze in die Berechnung ein, als für die Analyse der Test-Retest- Reliabilität herangezogen werden konnten. Dies resultiert daraus, dass zwar n = 485 Studienanfänger*innen zum dritten Messzeitpunkt Angaben zur SESW-Skala machten, einige von ihnen aber keine Angaben zu Abbruchintentionen machten. Der zum ersten Messzeitpunkt (Beginn erstes Semester) erfasste SESW-Skalenwerte wies einen bedeutsamen Zusammenhang mit der am Ende der Studieneinstiegsphase berichteten Abbruchintention auf: rs = .16, p < .001 (N = 424). Ebenfalls bedeutsam war der Zusammenhang mit der Studienzufriedenheit (rs = .14, p = .003, Skala nach Hiemisch et al., 2005, 9 Items, Cronbachs α= .82 , N = 424). Dies ist als Beleg für die prädiktive Validität der SESW-Skala zu werten.
Deskriptive Statistiken
Zunächst wurde die Verteilung des SESW-Skalenwerts in der Vergleichsstichprobe auf Normalität geprüft: Sowohl der durchgeführte Kolmogorov-Smirnov-Test als auch der Shapiro-Wilk-Test wurden signifikant: D (1842) = .99, p < .01 and W (1842) = .98, p < .01. Das bedeutet, dass keine Normalver- teilung vorliegt. Der Mittelwert der Verteilung liegt oberhalb der Mitte der Antwortskala (1 bis 5) bei M = 4.02 (SD = 0.55), die Schiefe beträgt Sch = -.50 (SE = 0.06) und die Kurtosis K = 0.52 (SE = 0.11). Zudem ist die Verteilung linksschief und rechtssteil. Man kann hier von einem Deckeneffekt sprechen.
Vergleichswerte
Eine Tabelle mit T-Werten (Normtabelle) zur SESW-Skala findet sich hier. Sie basiert auf den im Wintersemester 2018/2019 erhobenen Daten der oben beschriebenen Vergleichsstichprobe (N = 1842 Studienanfänger*innen). Ein Blick auf die Vergleichstabelle unterstreicht, was oben bereits ausgeführt ist: Die SESW-Skala ist als Screening-Instrument für Studieneinsteigsselbstwirksamkeit konzipiert und kann daher im unteren Ausprägungsbereich der SESW am besten differenzieren, eignet sich aber nicht für eine Differenzierung im oberen Bereich.
Nebengütekriterien
Ökonomie
Mit nur drei bis fünf Minuten Bearbeitungszeit ist die SESW-Skala ein ökonomisches Instrument, welches sich auch zum Einsatz in Panelstudien eignet.
Messinvarianz
Wie bereits unter Stichproben erwähnt, wurden Daten aus drei Längsschnittstudien verwendet, um die prädiktive Validität der SESW-Skala zu untersuchen. Das Vorliegen von Daten aus drei unabhängigen Jahrgängen ermöglicht auch die Exploration der Messinvarianz der SESW-Skala über die Jahrgänge hinweg.
Konkret wurde geprüft, ob das unter Validität dargestellte hierarchische Modell der SESW die Daten aus allen drei Jahrgängen gleichermaßen gut abbildet. Zunächst sind im Folgenden die Modellfitindizes pro Jahrgang aufgeführt:
Jahrgang 1: SRMR = .057, CFI = .869, RMSEA = .080 [.063; .106]
Jahrgang 2: SRMR = .074, CFI = .863, RMSEA = .076 [.049; .100]
Jahrgang 3: SRMR = .071, CFI = .844, RMSEA = .095 [.760; .114]
Das hierarchische Modell passt folglich relativ gut zu den Daten aus allen drei Jahrgängen, wobei die Fitindizes rein nominell etwas hinter denen, die anhand der Vergleichsstichprobe ermittelt wurden (siehe oben unter Validität), zurückbleiben. Neben dieser visuellen Inspektion der Fitindizes je Jahrgang, empfiehlt sich eine umfassende Invarianztestung, mit der die Frage beantwortet werden soll: Ist in allen drei Jahrgängen die gleiche (latente) Struktur zu finden und die SESW-Skala für alle drei (und damit ggf. auch für viele andere) Jahrgänge geeignet, um die Studieneinstiegsselbstwirksamkeit zu erfassen? Mit anderen Worten: Ist die Skala invariant über verschiedene Jahrgänge?
Zunächst soll das Konzept der Messinvarianztestungen kurz erläutert werden. Dabei ist zwischen verschiedenen Stufen von Invarianz zu unterschieden, die unterschiedlich strenge Annahmen umfassen. Im Dorsch-Lexikon der Psychologie findet sich folgende Definition von Messvarianz gemäß Eid (2017):
Messvarianz ist gegeben, wenn ein Set von Items [...] in versch. Populationen und/oder unter versch. Bedingungen (z. B. Messzeitpunkten) dasselbe Konstrukt erfasst. Messvarianz ist notwendig, um Gruppenunterschiede (z. B. Unterschiede zw. versch. Kulturen) bzw. Veränderungen in den Verteilungskennwerten (z. B. Mittelwerten, Varianzen) oder indiv. Werten als Gruppenunterschiede in Konstruktausprägungen bzw. als Veränderungen in Konstruktausprägungen interpretieren zu können. [...] Je nach Skalenniveau der Items und der Konstrukte (latente Variablen) können zur Analyse der Messvarianz Modelle der Klassischen Testtheorie, Item-Response-Theorie (IRT), Latenten Klassenanalyse oder der latenten Profilanalyse herangezogen werden. Messvarianz ist gegeben, wenn die Items in versch. Populationen bzw. unter versch. Bedingungen in derselben Weise mit dem Konstrukt (Variable, latente) verknüpft sind. I. R. der Faktorenanalyse unterscheidet man drei Arten von Messvarianz:
- Schwache Messvarianz liegt vor, wenn sich die Faktorladungen zw. Populationen bzw. Bedingungen nicht unterscheiden.
- Bei starker Messvarianz wird zusätzlich angenommen, dass auch die Achsenabschnitte gleich sind.
- Strikte Messvarianz setzt zusätzlich Gleichheit der Messfehlervarianzen voraus.
Dabei ist anzumerken, dass die Begrifflichkeiten in der Literatur nicht ganz einheitlich sind. So werden oft metrische und schwache Messinvarianz sowie skalare und starke Messinvarianz äquivalent verwendet.
Vandenberg und Lance (2000) erläutern in ihrem Artikel, welche Bedeutung Messinvarianz für die Generalisierbarkeit empirischer Ergebnisse hat und sprechen konkrete Empfehlungen für die Durchführung von Messinvarianzprüfungen aus.
Mit Hilfe des R-Pakets semTools von Jorgensen et al. (2018) wurde die Messinvarianz des hierarchischen Modells über die drei Jahrgänge hinweg geprüft. Hierbei wird entsprechend ein schrittweises Vorgehen angewendet. Zunächst wird geprüft, ob das Modell (die hierarchische Struktur der SESW-Skala) in allen drei Jahrgängen einen guten Fit aufweist. Dann werden in den nächsten Schritten jeweils immer mehr Restriktionen zur Modellspezifikation hinzugefügt, die „bei weiterhin guten Modellfit " die entsprechende Messinvarianzstufe indizieren. Das bedeutet, dass dann mit den unten ausgeführten zusätzlichen Restriktionen jeweils erneut der Modellfit beurteilt wird. Verschlechtert sich dieser nicht signifikant, so gilt die jeweilige Invarianzstufe als belegt. Dabei sind die Stufen aufeinander aufbauend, das bedeutet, sobald auf einer Stufe kein guter Fit mehr vorliegt, ist das auf der vorherigen Stufe bestätigte Messinvarianz-Niveau das maximal anzunehmende. Es werden dann keine weiteren (strikteren) Restriktionen mehr getestet.
Das schrittweise Vorgehen läuft im Detail nach folgendem Schema ab: Begonnen wird mit der einfachsten Variante, der konfiguralen Invarianz, bei der lediglich spezifiziert wird, dass der Modellfit über alle drei Jahrgänge hinweg gleich gut ist. Das bedeutet, im ersten Schritt wird im Fall der SESW-Skala getestet, ob die Modellstruktur als Ganzes zu den Daten des jeweiligen Jahrgangs passt. Methodisch geht es hier also um die Frage, ob für jeden Jahrgang die Faktorstruktur in den Daten, durch das hierarchische Modell adäquat abgebildet werden kann.
Im nächsten Schritt wird dann spezifiziert, dass auch die Faktorladungen über alle Jahrgänge hinweg gleich sein sollen. Trifft das zu, so kann die schwache (also die metrische) Invarianz als gegeben angenommen werden.
Im dritten Schritt wird zudem spezifiziert, dass die Achsenabschnitte der manifesten Variablen, über alle Jahrgänge hinweg gleich sind. Passt das so restringierte Modell weiterhin gut, kann die starke (also skalare) Messinvarianz als gegeben angenommen werden.
Im nächsten Schritt wird weiter spezifiziert, dass ebenfalls die Fehlervarianzen über alle drei Jahrgänge hinweg gleich sein sollen. Würde der Modellfit weiterhin gut sein, so kann von strikter Messinvarianz ausgegangen werden.
Tabelle 6 zeigt die Modellfitindizes für das Strukturmodell der SESW-Skala für die verschiedenen, aufeinander folgenden Messinvarianzstufen. Hierbei wurde neben den bereits oben berichteten Fitindizes (CFI, SRMR und RMSEA) auch der korrigierte ΧSB2-Wert herangezogen, der bei nichtnormalverteilten Daten statt dem unkorrigierten empfohlen wird (Satorra & Bentler, 2001, 2010).
Tabelle 6
Messinvarianzprüfung der SESW-Skala über drei Jahrgänge hinweg
|
Messinvarianz-Stufe |
ΧSB2 |
df |
ΧSB2 / df |
CFI |
RMSEA |
SRMR |
|
konfigurale |
381.34 |
186 |
2.05 |
.848 |
.086 |
.067 |
|
metrische |
403.10 |
210 |
1.92 |
.850 |
.081 |
.078 |
|
skalare |
416.08 |
228 |
1.82 |
.854 |
.076 |
.079 |
|
strikte |
438.44 |
254 |
1.73 |
.856 |
.072 |
.083 |
Anmerkung. N = 1086.
Vergleicht man die Fitindizes für das Modell unter den Restriktionen der konfiguralen Invarianz (erste Zeile in in Tabelle 6 ) mit denen für das Modell unter den Restriktionen für metrische Invarianz (zweite Zeile in in Tabelle 6), so zeigt sich kein bedeutsamer Unterschied im Fit, was bedeutet, dass sowohl die erste als auch die zweite Stufe der Invarianztestung als erfolgreich absolviert verstanden werden kann. Die Differenzen liegen jeweils (bis auf eine Ausnahme im Vergleich der ersten mit der zweiten Zeile in Bezug auf den SRMR: Δ SRMR = .011) innerhalb gängiger Toleranzgrenzen (Chen, 2007) für nichtsignifikante Änderungen im Modellfit: SOLL für ΔCFI < .010, SOLL für Δ RMSEA < .015 und SOLL für Δ SRMR < .010.
Vergleicht man weiter die zweite Zeile in in Tabelle 6 mit der dritten, in der die Fitindizes für das Modell unter den Restriktionen skalarer (starker) Invarianz aufgeführt sind, so zeigt sich das gleiche Muster: keine signifikante Verschlechterung des Modellfits. Gleiches gilt für den Vergleich der dritten mit der vierten Zeile in in Tabelle 6.
Daher kann angenommen werden, dass die SESW-Skala strikte Messinvarianz über die drei Jahrgänge hinweg aufweist. Das bedeutet, dass das hierarchische Modell über die drei Jahrgänge hinweg gleiche Faktorladungen und gleiche Achsenabschnitte für die manifesten Variablen (die beobachteten Items) aufweist. Zudem kann von äquivalenten Fehlervarianzen ausgegangen werden.
An dieser Stelle sei explizit angemerkt, dass sich (betrachtet man den CFI und den RMSEA) tatsächlich der Modellfit durch die Hinzunahme weiterer Restriktionen verbessert hat, wobei die Höhe des CFI insgesamt nicht im guten Bereich liegt, die Höhe des RMSEA und des SRMR jedoch innerhalb der gängigen Grenzen für akzeptablen bzw. guten Modellfit liegen.
Auf Basis der somit nachgewiesenen strikten Messinvarianz der Skala kann diese für den Einsatz in verschiedensten Jahrgängen empfohlen werden, da davon auszugehen ist, dass ihr Nutzen zur Erfassung der Studieneinstiegsselbstwirksamkeit über Jahrgänge hinweg generalisierbar ist.
Danksagung
Dank gilt den Kolleg*innen der Stabstelle StL (Studium, Lehre, Weiterbildung, Qualitätssicherung; Servicestelle Lehrevaluation) der Justus-Liebig-Universität Gießen, die die Erhebung der Vergleichsstichprobe ermöglichten.
Pascale Stephanie Petri, Justus-Liebig-Universität Gießen, Psychologische Diagnostik, Otto-Behaghel-Straße 10F, D-35394 Gießen, E-Mail: pascale.s.petri@psychol.uni-giessen.de
Datenquellen
Die SESW-Skala wurde im Rahmen eines Dissertationsprojektes entwickelt. Daher enthält diese Handreichung Auszüge aus der entsprechenden Dissertationsschrift:
Petri, P.S. (eingereicht). Ein Prozessmodell des Studieneinstiegs: Differentielle Aspekte studiumsbezogener Kognitionen und deren Effekte auf Studienerfolg und Studienabbruch (unveröffentlichte Dissertation). Justus-Liebig-Universität, Gießen.